 Blogᒼ
Blogᒼ爬虫是一种程序,它可以自动地访问网站并抓取数据。但是,如果爬虫发送的请求过于频繁,服务器可能会将其 IP 地址屏蔽,这就需要使用代理 IP 来访问,然而高质量的代理 IP 价格通常较贵。因此,我们可以使用百度 APP 的代理进行数据抓取。
代理 IP 信息:
- HOST: cloudnproxy.baidu.com
- PORT: 443
需要注意的是,百度代理会校验 User-Agent。因此,我们需要在正常的 User-Agent 后面追加 baiduboxapp/13.10.0.10。有些实现会要求在 Headers 中添加 X-T5-Auth,但经过测试,这个 key 其实是不必要的。
代码实现
import requests
def send_request_via_proxy(*args, **kwargs):
baidu_proxy = 'cloudnproxy.baidu.com:443'
kwargs['proxies'] = {'http': baidu_proxy, 'https': baidu_proxy}
if 'headers' not in kwargs:
kwargs['headers'] = {}
if 'User-Agent' not in kwargs['headers']:
kwargs['headers']['User-Agent'] = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 ' \
'(KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36'
kwargs['headers']['User-Agent'] += ' baiduboxapp/13.10.0.10'
# kwargs['headers']['X-T5-Auth'] = '196289709'
resp = requests.request(*args, **kwargs)
return resp
if __name__ == '__main__':
api = 'https://pubstatic.b0.upaiyun.com/?_upnode'
ip_info = send_request_via_proxy('GET', api).json()
print(ip_info['remote_addr'])
print(ip_info['remote_addr_location'])
运行代码,可以看到我们的 IP 地址已经变成了百度的代理 IP 地址
$ python3 proxy-test.py
180.101.81.32
{'country': '中国', 'isp': '电信', 'province': '江苏', 'continent': '亚洲', 'city': '苏州'}
每次请求的出口 IP 随机,这样就可以避免被服务器屏蔽了。
代理 IP 池
使用 ping 命令,可以获取多个地点的入口 IP,但是出口 IP 仍然是随机的,这点需要注意。
220.181.7.1 中国北京电信
220.181.33.174 中国北京电信
220.181.111.189 中国北京电信
180.97.93.202 中国江苏苏州 电信
180.97.104.168 中国江苏南京 电信
14.215.179.244 中国广东广州 电信
157.0.148.53 中国江苏苏州 联通
153.3.236.22 中国江苏南京 联通
110.242.70.69 中国河北保定 联通
110.242.70.68 中国河北保定 联通
157.255.78.51 中国广东广州 联通
36.152.45.98 中国江苏南京 移动
36.152.45.97 中国江苏南京 移动
缺点
因为这个代理本身就很多用户在使用,所以一些反爬比较严格的网站可能会拦截这个代理的请求。
其实这个代理有一些其他的用法(比如流量卡),但是可能涉及到一些法律问题,这里就不多介绍。


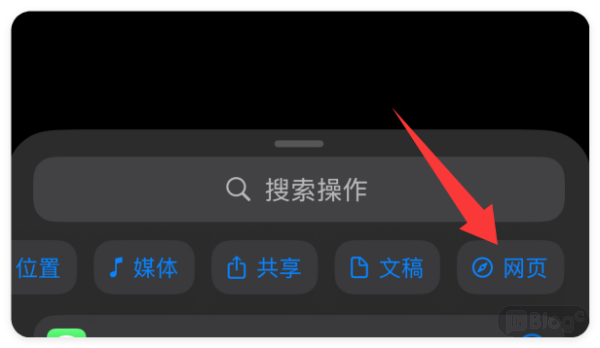
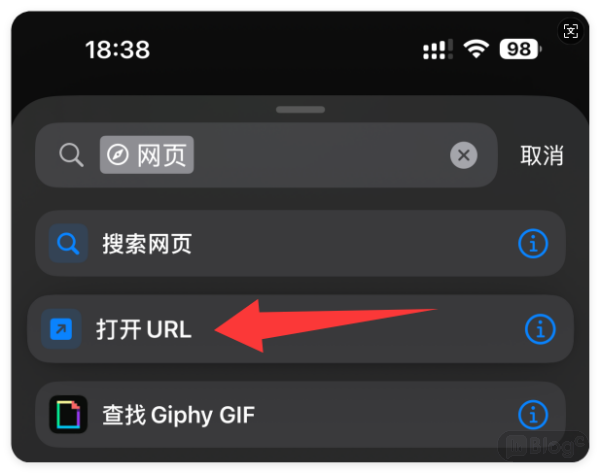
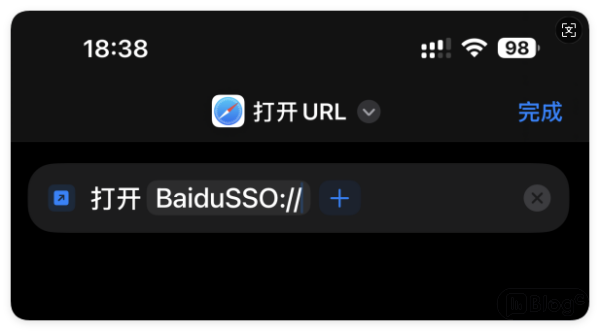
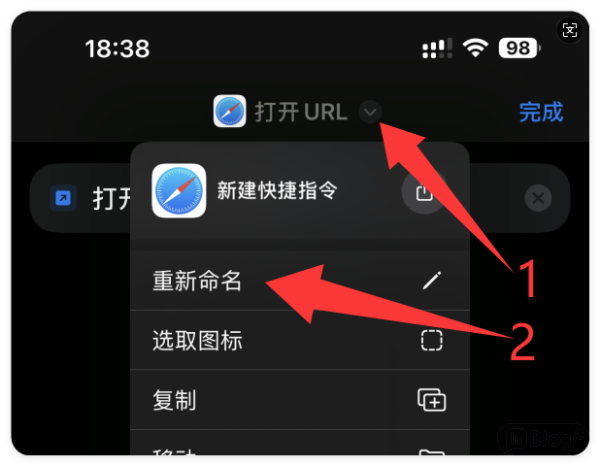





")
")
")
")
")
")
")
")
")